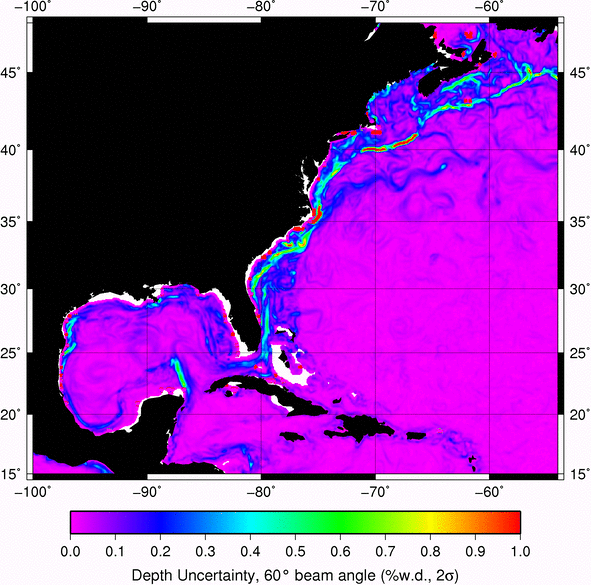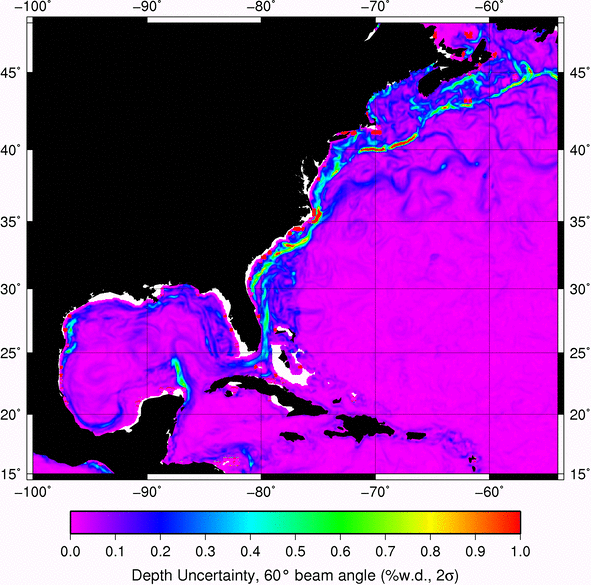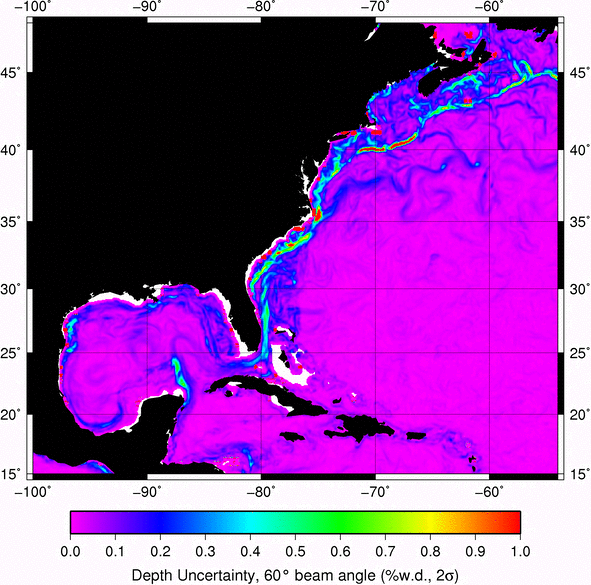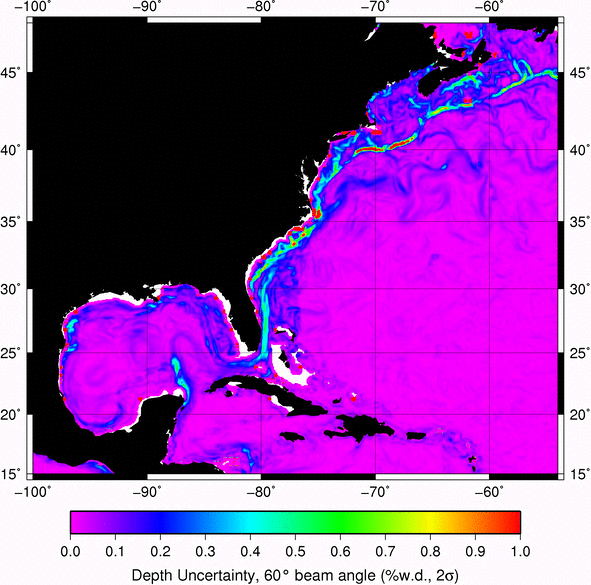
Have fun!!
#!/usr/bin/env python2.6
import os
import struct
import time
import sys
file_count=0
debug=False
dir="split"
for filename in sys.argv:
file_count += 1
if (file_count == 1):
# I'm too lazy to parse command line args so just skipping over the
# script name (which is arg zero in the list)
continue
file = open(filename, 'rb')
filesize = os.path.getsize(filename)
# What is the path to the input file without the filename?
filepath=os.path.dirname(filename)
fileprefix=os.path.basename(filename)
if debug or True:
print "Doing file",filename
print "Got file path",filepath
print "Got file basename",fileprefix
# Join the file's directory path with the usual output subdirectory name
outdir=os.path.join(filepath,dir)
if not os.path.exists(outdir):
os.makedirs(outdir)
split_allname = os.path.join(outdir, fileprefix)
split_wcdname = split_allname.replace(".all",".wcd")
if debug or True:
print filename, "will split into", split_allname, split_wcdname
if not os.path.exists(split_allname):
split_allfile = open(split_allname,"wb")
split_wcdfile = open(split_wcdname,"wb")
else:
print "Skipping", filename, "since it's already split!"
file.close()
continue
last_percent = 0
while True:
# Make sure we don't try to read beyond the EOF
if (file.tell() + 6 > filesize):
break
line = file.read(6)
header = struct.unpack("<IBB",line)
rawlength=line[0:3]
length = header[0]
stx = header[1]
id = header[2]
if (stx != 2):
if debug:
print 'STX not found, trying next datagram at position',file.tell()-5
file.seek(-5,1)
continue
if debug:
print 'STX found, going to try for ETX now'
# Make sure we don't try to read beyond the EOF
if (file.tell() + (length-5) > filesize):
file.seek(-5,1)
continue
file.seek(length-5,1)
# Make sure we don't try to read beyond the EOF
if (file.tell() + 3 > filesize):
break
line = file.read(3)
footer = struct.unpack("<BH",line)
etx = footer[0]
checksum = footer[1]
if (etx != 3):
if debug:
print 'ETX not found, trying next datagram at position',file.tell()-(length+3)
file.seek(-(length+3),1)
continue
# Rewind to very beginning of the datagram, including the length field
file.seek(-(length+4),1)
data = file.read(length+4)
if debug:
print "Got id", id, "and length", length
if (id == 0x49 or id == 0x69 or id == 0x52 or id == 0x55):
# Stuff for both files
split_allfile.write(data)
split_wcdfile.write(data)
elif (id == 0x6B):
# Just for the watercolumn file
split_wcdfile.write(data)
else:
# Everything else goes into the raw file
split_allfile.write(data)
percent=int(100.0 * file.tell()/filesize)
if (percent%5 == 0 and percent != last_percent):
print percent, "% done, ALL:",split_allfile.tell()," WCD:",split_wcdfile.tell()
last_percent = percent
if file.tell() >= filesize:
break
file.close()
split_allfile.close()
split_wcdfile.close()
print 'All done!'